Building smarter travel app with RAG
Real world use case for building RAG and learning from the building. Building fully functional travel itinerary planner with AI agents and RAG.
TLDR;
Building travel itinerary planner with AI agents and RAG.
Building smarter travel app with RAG
For me, travelling is the ultimate freedom.
I like planning the trips, but the moment I step into journey, I drop the plans. I make changes on the fly, I follow the flow, and in the most days, I’m not even sure where I am going to be in the next 2 days. On certain nights, I go to bed without knowing where I am heading the next morning.
This style of travel is not for everyone. It has its downsides: limited options for hotels, missed trains, stress over the last-minute tickets, and the nights researching the options instead of having the good night rest.
But I love it! I love it so much, that I decided to start to build own hobby project to reduce the pain even for a little.
So here it is, my own attempt on creating itineraries by using AI agents!
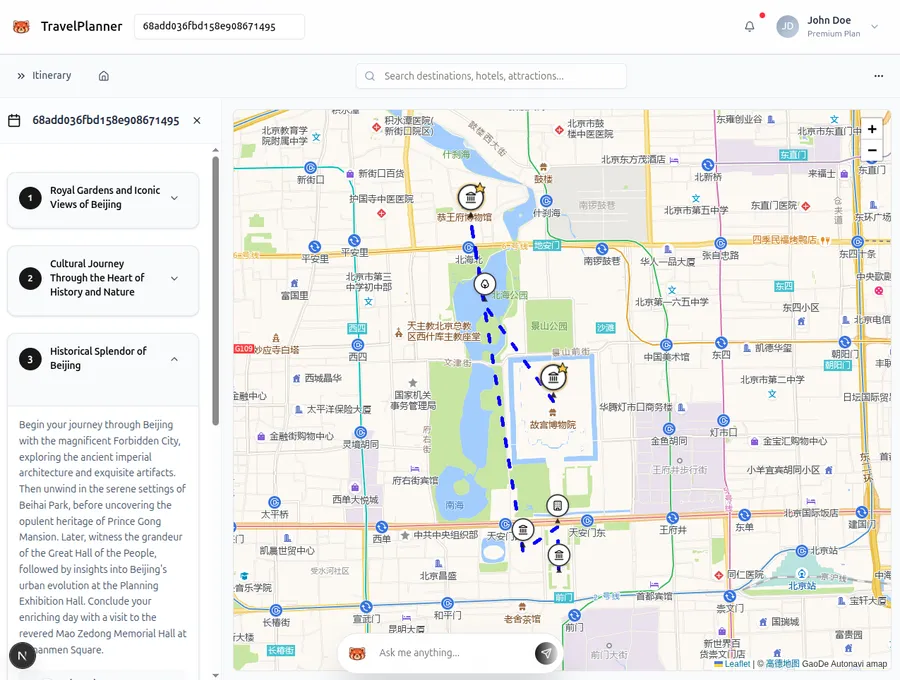
The video showcases itinerary creation by the user prompt. For this example I used “Give me a 3-day cultural trip in Beijing focused on history and architecture”.
However, this part of the website is not the part I want to focus! But the adding of attractions when the itinerary has been created!
Adding attractions to the itinerary
The goal is simple: Analyze the user prompt, find the attractions user means by their prompt, then add them to the current itinerary. This might sound easy, but without help of embeddings (I explain them later), this is quite challenging task.
Version 1, without embeddings
Here was the initial data flow of my version 1.
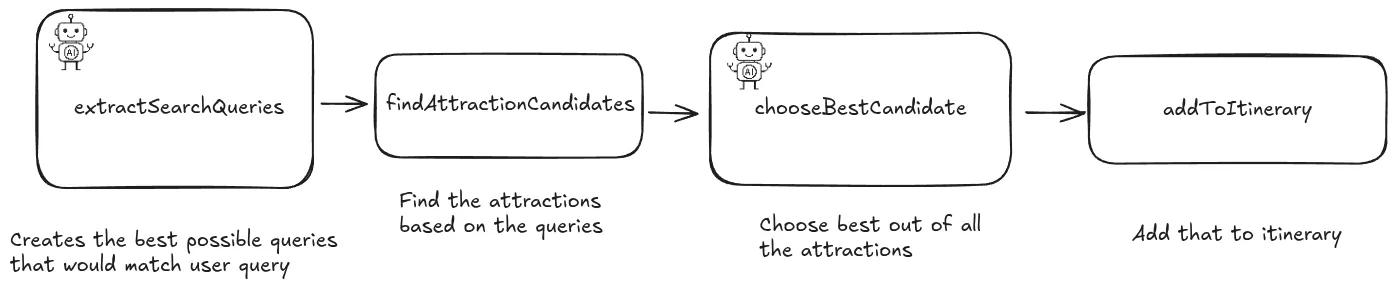
I made this work, but it worked unreliably. This is due to bottleneck of the first step, creating queries to the database based on the user prompt.
So why creating queries is hard task? This is due to many factors:
- Users can have very vague prompts.
e.g. “I want beautiful museum to the day 1!”
How could the AI agent translate this into a good query to the database? Maybe first add query filter based on the location, e.g. only the attractions in Beijing.
Next would be create some search query based on the user prompt. E.g. “museum”. The agent could generate all kinds of different queries, but something like “beautiful” is very hard task to translate to the database query.
- Synonyms and variations of words
A user might say “ancient palace”, “imperial residence”, or “old emperor’s home” — all could mean the same thing (the Forbidden City), but the database may only contain “Forbidden City” or “Palace Museum”.
- Ambiguity of natural language
“Temple” could mean a Buddhist temple, Taoist temple, or even a Confucian shrine. Without extra context, the system doesn’t know which type the user means.
“Biggest museum”, is that biggest by area, by number of exhibits, or by popularity?
This list could be continued, e.g. subjective attributes (famous, hidden, must-see, relaxing words can humans understand, but database have no notion ofthese words!), different languages, no broad concepts (e.g. what is famous in terms of database?), too many constraints (if constrains too much, there is chance of not finding any attractions).
Overall, adding attraction to the itinerary by just creating queries is very hard due to translation of natural language to the database queries.
Embeddings
Wouldn’t it be cool if by just writing “I want most famous attractions in Beijing”, it would map automatically to the attractions that match “most famous” and in “Beijing”. So instead of some query parameters, we match the “values” of different concepts.
For LLMs, we can give that given prompt, and LLM knows the answer! So the vast amount of knowledge that the LLM was trained on, contains this information! LLMs in sense know how to map concepts as “famous” to different tokens!
This is where embeddings come to play! With the LLM’s we can actually represent the prompts as long list of floating point numbers:
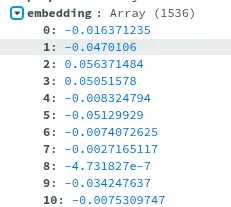
Different prompts give different list of floats, but the values are not random! The values are closer to each other when the “concepts” are closer to each other. In a sense, if two list of values are close to each other, the meaning is similar.
But as embeddings are list of floats, we can think of them as vectors! So the similarity actually can be expressed as cosine similarity, which is just fancy way to say how much angle there is between the vectors. The smaller the angle between vectors, the closer they are in similarity.
Generating embeddings
I chose to use openAI’s “text-embedding-3-small” to give embeddings for each of my attraction.
Each embedding is generated by giving it prompt, for this I just gave it the most important information about the attraction:
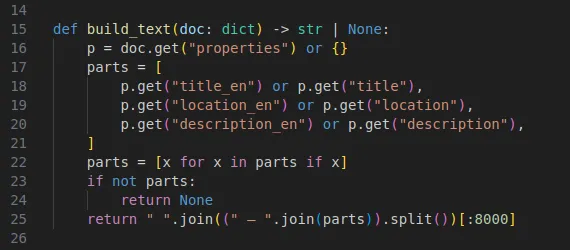
Now, the embedding array is information about the attraction, e.g. its name, its description and it’s location.
The best thing about creating a large amount of embeddings as background task, is that creating batch requests are incredible cheap!
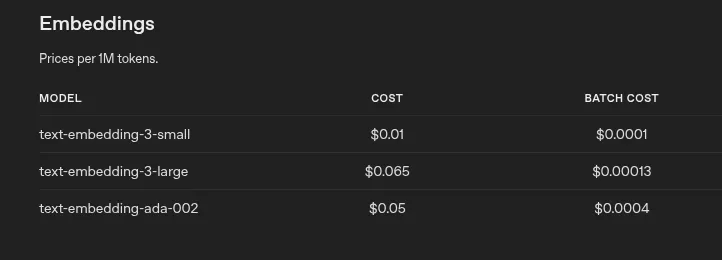
I chose to use this batch API for creating all of my embeddings for the attractions (over 10 000 attractions!).
Version 2: Embeddings
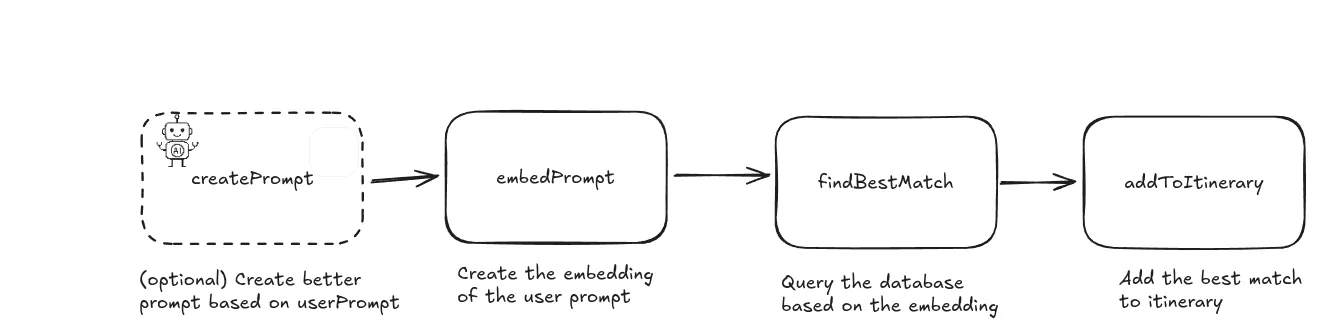
Here we have the new data flow with embeddings.
So why this is better?
Our data flow is more deterministic. We don’t rely on the LLM to create good queries. Same prompt will always give same embedding. The workflow handles the search by first creating the embedding for the user prompt (or by creating the prompt based on user prompt with LLM). The rest of the workflow is just finding the closest embeddings to the user prompt embedding and saving it to database!
All of this achieved us to create deterministic way to add attraction to the itinerary, that can smartly match user prompt, no matter how complex the query is! Overall, we do not need to care about the queries, we just have to get the closest embeddings to the user prompt!
Demo
Let’s see the RAG in action!
In the video we give very vague prompt that our old system would not be able to handle, at least not reliably: “I want museum with animals and plants in Beijing to day 3”. Due to the power of embeddings, the system was able to find the “Beijing Museum of Natural History” from all of the 10 000+ attractions!
This was just glimpse of the power of RAG and embeddings inside agentic workflows. I try to keep posting about the development of this project, so stay tuned for more!