Automated RAG Evaluation without Human Labels (Ragas in Practice)
Learning and building automated evaluation system with Ragas. Can LLMs automatically evaluate RAG systems? Are human labels always needed?
Automated RAG Evaluation without Human Labels (Ragas in Practice)
Creating initial retrieval-augmented generation (RAG) systems is relatively straightforward with the help of LLM provider platforms and vector database providers. However, evaluating and improving these systems is a technical challenge.
Everything is related to the measurements. To improve a RAG system, you need to identify what needs improvement. And it is hard to optimize a workflow without enough information on how it behaves or what the challenges of the system are.
One way to tackle this is by generating human-labeled golden answers or by creating an evaluation set with human-labeled outputs to create a metric. But this is also tiresome. Evaluations doesn’t really scale, but without metrics, optimization is also blind.
However, we can automate the evaluation with some metrics that do not need any human labeling at all. In this blog, I will automatic Retrieval Augmented Generation Assessment (Ragas) works, and how I used ragas github project to automatically run evaluations on user queries to my system.
This enables regression detection, version-to-version comparison, and evidence-driven prompt iteration.
Retrieval Augmented Generation Assessment (Ragas)
Generating labels for the evaluations is usually expensive. The reason is simple: they need to be great in order to get good outputs with the optimization. This usually means it needs human intervention or human labeling of the evals. And I hate doing that! What I want is to know how the system behaves with the least amount of human interventions as possible. And Ragas can help in that.
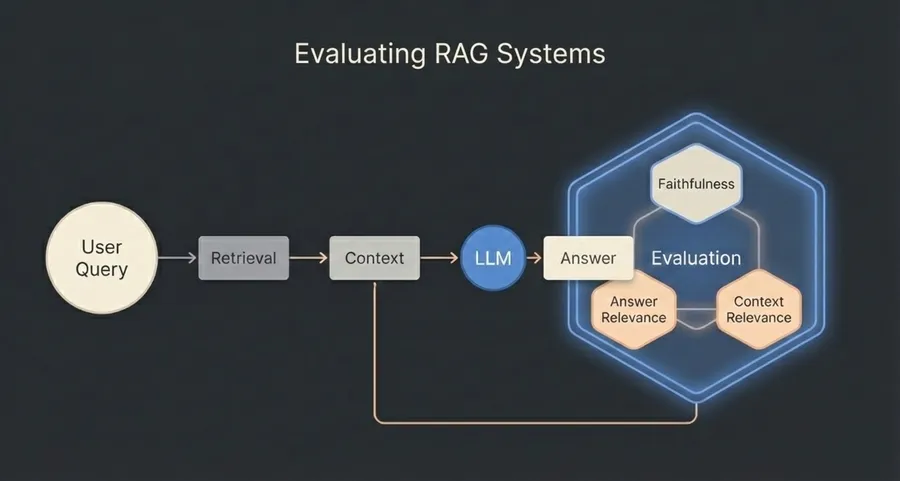
Ragas paper is all about how to automatically evaluate RAG systems. The basic idea is that we can generate a list of different metrics, where LLMs themselves can be used as judges of the final output structure. It doesn’t necessarily measure the “correctness” of the system, but more like alignment between the system components. E.g., did this system answer the user’s question? Did this system use relevant context in the answer? Are the facts in the answer also found in its context?
Three Metrics
The paper itself talks about 3 different metrics that can be used to automatically do measurements on the RAG systems: Faithfulness, Answer relevance, and Context relevance. And these three metrics can then be used, for example, to optimize the system or monitor how well it is doing with the current version.
Faithfulness
Faithfulness metrics answer the question “Did the LLM hallucinate the answer?”. So it is basically check if the LLM answer was actually based on the given context.
How this is done is by first generating statements from the answer:
Given a question and an answer, create one or more statements from each
sentence in the given answer.
question: [question] answer: [answer]
and then checking if these statements are found in the context:
Consider the given context and the following statements, then determine
whether they are supported by the information present in the context.
Provide a brief explanation for each statement before arriving at the verdict (Yes/No).
Provide a final verdict for each statement in order at the end of the given
format. Do not deviate from the specified format.
statement: [statement 1] … statement: [statement n]
Then the final faithfulness score can be calculated by:
Answer Relevance
Answer relevance is about whether the LLMs directly answer the user’s question. The trick for calculating this is quite smart:
We first generate a bunch of hypothetical questions based on the answer to the query:
Generate a question for the given answer. answer: [answer]
Then we use an embedding model to embed both the user question and the generated hypothetical questions. After that, we can utilize the vectors to calculate the similarity score between these questions:
Where q is the original embedded question, and q_i is the generated embedded question. The closer the similarity between the questions, the higher the answer relevance score.
Context Relevance
Finally, we can also use LLM to answer how relevant the context is for the final answer.
After running the LLM, we have both the context and the answer, e.g., the RAG retrieved documents, and the final answer. We can ask LLM to give all the sentences that helped us answer the question from the context:
Please extract relevant sentences from the provided context that can
potentially help answer the following question.
If no relevant sentences are found, or if you believe the question cannot be answered
from the given context, return the phrase “Insufficient Information”.
While extracting candidate sentences, you’re not allowed to make any changes
to sentences from the given context.
Then the Context relevance (CR) is just
What is good about these three metrics is that they do not need a human to label, so we can run them automatically in our own system.
Implementation
I tried to evaluate my Hyde blog’s endpoint for retrieving the most relevant attraction to the user query. The code in the endpoint itself is very minimal. After each run in the system, I store the information of the run in the database:
export type EvalRun = {
runId: string;
model: string; //What LLM used
systemHash: string; // Hash of the current prompts == version
question: string; // User input
answer: string; // LLM output
contexts: string[]; // All context (including RAG retrieved documents)
ragas?: {
// This is calculated in later
answer_relevancy?: number;
faithfulness?: number;
context_utilization?: number;
evaluatedAt?: string;
[metric: string]: number | string | undefined;
};
};After that, I created a script that finds all the EvalRuns that do not contain the ragas property and calculates that property for them. I deliberately run evaluations asynchronously and decouple them from inference. This keeps user latency unaffected and allows backfilling metrics for historical runs whenever metrics or prompts change. For that, I used the ragas package, which is a library for generating evaluations.
The original Ragas paper defines these three core metrics. The ragas library generalizes this idea and adds additional LLM- and embedding-based metrics, orchestration, and experiment tracking. In this post, I intentionally focus only on the paper-aligned metrics to avoid metric drift.
The script itself can be summarized to its evaluation function:
async def run_experiment_over_dataset(
dataset: RagasDataset,
llm,
embeddings,
experiment_name: str,
):
answer_rel = AnswerRelevancy(llm=llm, embeddings=embeddings)
faith = Faithfulness(llm=llm)
context_util = ContextUtilization(llm=llm)
@experiment()
async def score_row(row): # row == one EvalRun
q = row.get("question", "")
a = row.get("answer", "")
ctxs = row.get("contexts", [])
ar = await answer_rel.ascore(user_input=q, response=a)
ff = await faith.ascore(user_input=q, response=a, retrieved_contexts=ctxs)
cu = await context_util.ascore(user_input=q, response=a, retrieved_contexts=ctxs)
return {
**row,
"answer_relevancy": ar.value,
"faithfulness": ff.value,
"context_utilization": cu.value,
}
results = await score_row.arun(dataset, name=experiment_name)
return resultsWhere I first generate the metrics I am interested in faithfulness, answer relevance, and context utilization (is context used in the answers). Ragas library has a lot of different metrics to use, but I chose to go with these simple for now.
Now the code automatically stores the result of the run due to ragas’s @experiment decorator.
Observability & Optimization
The real value of this experiment comes from the observability and how the output guides our decisions. The goal was to make a system where we can easily compare different versions, and visibly see when regressions have happened.
For this, I created in my application a dashboard that reads this run information from different versions (different prompt hashes) and gives a clean UI for easy comparisons. For testing purposes, I created a small eval set that I can run automatically for different versions, and then show the results in the dashboard.
Here’s one example of the output where I run the Hyde endpoint with two different prompts.
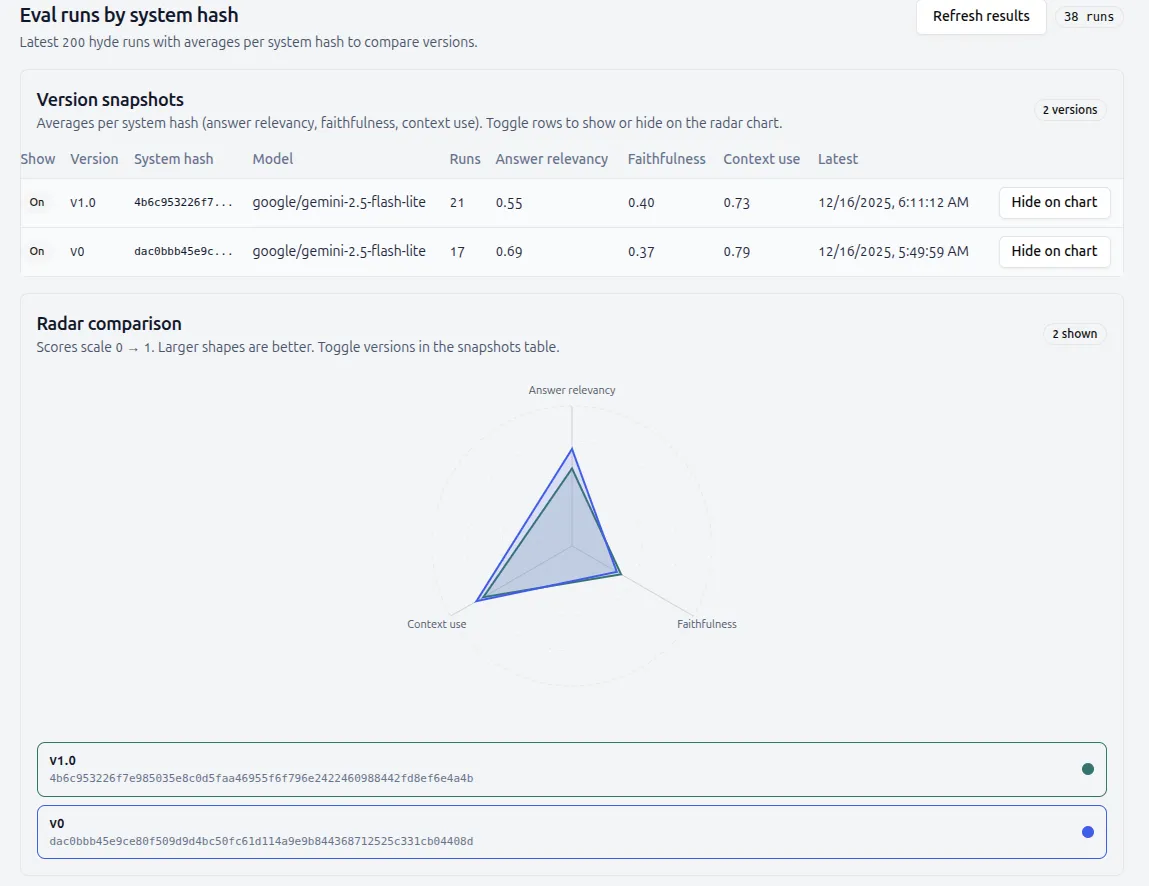
In the new version, I tried to make the faithfulness better, which it did, but regressed two other metrics in the process! Without having evals in the system, the comparisons would need to be made with “vibes,” even though the data clearly likes the old version better.
Limitations
Before making any conclusions, I still want to point out that these LLM-based metrics are ok, but also are not ground truth. The model would easily be made much stronger by using metrics that are based-on golden values (human labels).
The current system is not some magical metrics that make your system easily optimizable, but it gives me the start point even to think about what to optimize for. A larger eval set and better metrics can really make the model much better in the long run. I recommend looking more at the ragas package in terms of the metric options.
Conclusions
Automatic RAG evaluation won’t replace human judgment, but it dramatically reduces the guesswork. If you’re iterating on prompts, retrievers, or chunking strategies without metrics like these, you’re optimizing on intuition, not evidence.
In this blog, I demonstrated how to start using the learnings from the Ragas paper to your real system, and how to implement the automatic evaluations with ragas library. This way, we rely less on the “vibes” and can make more informed decisions. The ability to optimize is not far away when you get decent metrics that already run on your system automatically!