HyDE: Weaponizing Hallucinations for Better Retrieval
Explaining and building real use case for Hypothetical Document Embeddings (HyDE) to showcase that hallucinations are not always bad

HyDE: Weaponizing Hallucinations for Better Retrieval
Recently I have tried a fun experiment on my travel itinerary planner application. Instead of trying to do complex agent workflows with tool calls, I let the model hallucinate a itinerary (with possible many mistakes!) to my application first. Then I embedded the hallucinated document to retrieve real attraction data from my database!
And to my suprise: the results were better than I expected!
This is the core idea of HyDE (Hypothetical Document Embeddings), which uses hallucinations as a weapon to guide us to retrieve the most relevant document. In this blog, I’ll explain the power behind the HyDE, why hallucinations aren’t just a random noice, and show how I implemented HyDE in my own travel planner application.
Here’s video of what HyDE managed to do in my application: retrieving full itinerary day and it’s real attraction data super fast!
Optimizing Dense Retrieval
The point with the HyDE and with my travel itinerary example is both the same: we want to optimize dense retrieval. Dense retrieval uses high-dimensional learned embeddings to find documents by semantic similarity.
Consider you have a corpus of documents (or books etc). Each having their own content. We often than not have use cases where we want to find documents that are most relevant to us, e.g., if we like a one book in the library, we could wish to find all the books that are the most similar to our favorite book easily! This is “Dense retrieval”: finding the documents that are in embeddings most similar to other document.
Retrieval Augmented Generation (RAG) can handle these type of problems. As we know, LLMs have good knowledge on different concepts and semantics. We can utilize the these LLMs knowledge to create these similarity searches (using embedding models). For this to work, we first embed the both the query and the documents with a dedicated embedding model which outputs a vector. For each input we give the model, the embedding model outputs a vector representing that query.
What’s great about this, is that similar queries, and similar concepts are found to be more similar in terms of output vector. That means, in order to compare similarity between two documents, we just need to do basic vector math, two vectors being close in embedding space means the underlying texts are semantically similar. For example [0, 5 ,10 ]is closer to [1, 5, 9] than [8,6,0]
So the goal becomes: how do we best retrieve the most relevant documents? In my use case, how do I best retrieve all the attractions for my travel day when each of the attractions have one of these embedding vectors. Embedding user query such as “Give me day in beijing” could possible give some results that contain the word “beijing” in it, but it is not good. Why? Well, first of all, the query is too vague to give good semantics, it also lacks the semantic density to be close to specific attraction descriptions, and the attraction descriptions have place-specific content, which is not matched by the query.
HyDE overview
If your goal is to get most relevant documents, and it is done by vector similarity, we need to optimize the embeddings! The overall idea of HyDE is basically:
What if we would first generate hypothetical answer to the user query, and then embed the hallucinated document to find the real documents!
So instead of embedding the search query “Give me day in Beijing”, we first let LLM answer that question:
Morning — Temple of Heaven → Tiananmen Square → Forbidden City
- Temple of Heaven (天坛) — 8:00–9:00
Start early to see locals doing tai chi, dancing, and playing music.
Walk the main axis: Hall of Prayer for Good Harvests → Imperial Vault of Heaven → Circular Mound Altar. …
and then embed the answer and use that to retrieve the real data. As you can see, the LLM already started telling about certain attractions, however, the data it outputs might be hallucinated or contain mistakes!
The original question user asked might be too short, too vague, or just not that good. But using this hallucinated data has profound implications on retrieving the documents!
Hallucinations Are Your Friend
When we think of hallucinations, they in most use cases are seen just frustrating “bugs” that LLM happens to have. But that is not the case with HyDE, hallucinated output (or in this use-case the output that does not rely on any extrenal data, only on the model itself) is useful for retrieving the most relevant documents.
So the basic idea of HyDE was to embed this hallucinated answer and use that to retrieve the document, why does this work?
Hallucinated data is not random
Hallucinated data is not random. Every output comes from the model’s learned latent space, its internal semantic associations.The hallucinated document encodes semantic patterns of a correct answer, even if the details are wrong.
So the hallucainted answer “looks” like a correct answer, but is not correct! In the last blog, I talked about how LLM answers could be thought as trajectories that tend to go towards certain space. The hallucinated answer is a trajectory, which behaves like the correct trajectories, and is close to the space of correct answer, but can be slightly off.
Embeddings Compress Away the Wrong Details
When the embedding model generates the vector, the vector itself is always the same size. For example OpenAI’s embedding model “text-embedding-3-small” gives a vector of dimension 1536. If the used embedding model works like it should (good model), it should compress the core information to this rather small vector.
What does this imply is that core semantics and information is compressed, so the noise on the data (hallucinations, mistakes) etc. have less impact on the vector. Embeddings emphasize semantic meaning, so small factual mistakes matter less.
Hallucinations Ground the Retrieval
Now we have the hypothetical document embedding. What is good about it that it has the structure and semantics like a real answer. As the semantics are similar, it is much easier to search for real documents with it, as the embedded vector is semantically similar to the real documents in the database.
So, hallucinations can be useful, they also contain semantical information that can be used to dense retrieval. Instead of doing eveyrthing to not allow model to hallucinate information, we can use those hallucinations as embeddings to query the doucments we are interested in.
Here’s the full architecture of the HyDE from the official paper.
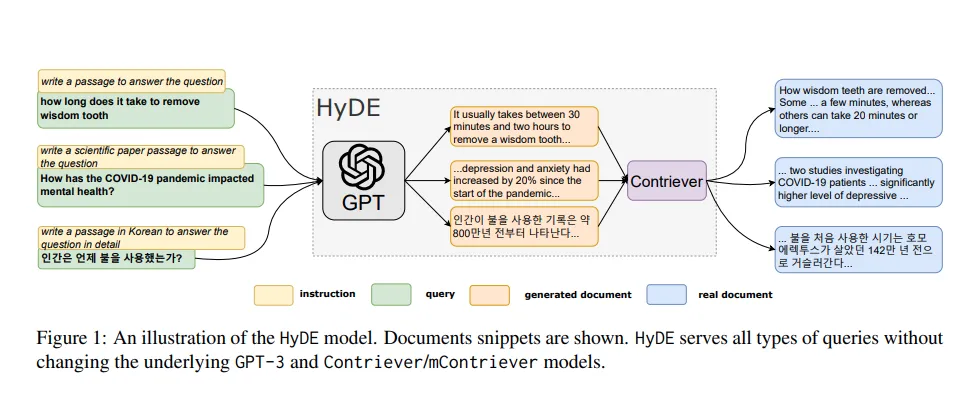
It shows all the steps I have also talked about: first generating hypothetical document, then embed it and use to retireve the most relevant documents (“contriever”).
Implementing HyDE in a App
Implementing HyDE is actually very simple, but even if it is simple, it gives suprisingly good answers. I used it in my travel planner to retrieve attractions from the database.
In my example, I have around 10 000 Chinese attractions in a database. Each with their own informations such as name, description, rating, etc. All of these attractions also have a vector embedding, generated by their most important information (city, name, description, rating, etc.).
The problem in the application is to retrieve these attractions based on user queries to generate best itinerary. Previously, I have been doing it with agents, that have tools to search attractions by certain criteria (e.g. area, rating), search nearby similar attractions, group attractions etc. This gets quite complex very easy.
However, with HyDE, retreiving can be done by first generating hypothetical itinerary, then embedding it’s outputs and return list of best matching attractions! I use Vercel’s AI SDK for my implementation, so here’s the sketch for the implementation:
- Generating the Hypothethical Itinerary
First step is to generate the hypothetical itinerary. If user wants to go to Beijing, it generates a day in Beijing:
const { object: plan } = await generateObject({
model: openrouter("google/gemini-2.5-flash-lite"),
system: `Draft a one-day plan. Return JSON with 3-5 items: [{name, summary, city?}]. Focus on real, well-known places; keep names clean.`,
messages: modelMessages, // User message
schema: z.object({
items: z.array(
z.object({
name: z.string(),
summary: z.string().optional(),
city: z.string().optional(),
})
),
}),
});Instead of returning single answer, I chose to give list of attractions that are all embedded. I noticed this working better, as if I only output single itinerary, the text would contain some words such as “Beijing” many times. So in the later retrieve step, the output would be mostly attractions which have the word “Beijing” in it. But if we embed each step of the itinerary, we can do searches based on the semantic similarity on attraction, instead of whole itinerary.
- Embed the Hypothetical Attractions
Now we embed the attractions:
const { embedding } = await embed({
model: openai.textEmbeddingModel("text-embedding-3-small"),
value: query, // Single attraction text
});which gives us the embedding vector representing single attraction in a hypothetical itinerary
- Search Attractions
Now we just search the best matching attraction with the embedding vector.
const matches = await searchAttractionsByEmbedding({
embedding,
limit: 1,
numCandidates: 300,
});This function just does vector search in my db (MongoDB) to retrieve best matching attraction.
- Generate the Itinerary
Now we have both the list of attractions, and the user query. So we can generate the final itinerary based on the real attractions:
const result = streamText({
model: openrouter("google/gemini-2.5-flash-lite"),
system: systemPrompt, // System prompt containing all the previous information
messages: convertToModelMessages(messages),
});and here’s the output for the query “Give me day in Beijing”:
From the 10 000 attractions, it managed to find the most relevant 4 attractions! This all information without relying on agents or tools is quite good, given how simple the workflow for it is. Of course, this is just a starting point, but HyDE approach can be real good basic implementation for many use cases in AI-native applications. For simplicity-sake, I just did the minimal implementation for HyDE in my application, but it could be quite interesting if HyDE capabilities could be given to agent, which could itself generate hypothetical documents, embed them, and then query real documents with the tool calls.
Conclusion
Hallucinations might not be as bad as we think of them. At least for me, learning about HyDE made me have different way of thinking about hallucinations. Instead of thinking them as mistakes, I started to think them as semantical hints for the real answer. And that is what the HyDE paper is about, optimising the dense retrieval with the hints given by the hypothetical documents.
The basic idea behind it is simple, but profound. Instead of battling to make the model hallucination-free with prompting, why not just use the hallucinations to guide us. LLMs complex hidden latent space is the one generating the hallucinations, it is based on the training data, so the answers it gives are not meaningless!
Building with HyDE actually showed that it’s not just a “toy”, it can be utilized in real applications, and the ideas behind it can be used in many use cases. It is great tool to know, when building AI-native applications.