Using LLMs to Augment My Travel App: Categorizing 10,000 Attractions Efficiently
Using LLMs to catergorize 10,000 attractions efficiently. Learning blog post how to utilize LLMs to augment my travel app.
Using LLMs to Augment My Travel App: Categorizing 10,000 Attractions Efficiently
Recently, I have been working on small side project. The idea is to build a travel map application to help myself in my backpacking trips.
The current context of the project is limited to China, which is more than enough for me handle for now (tens of thousands of attractions). While the basic functionality was already in place, I realized that it would be useful if I could categorize the attractions based on their official government rating and by their type.
The first step of categorizing the attractions was simple, as all the data for the attractions was available but just not in any good format. Simple web scraping was enough to get the all the data needed (around 10,000 officially rated attractions).
However, the second step of categorizing the attractions was a bit more challenging. As there is no official categorization for the attractions, nor the big Chinese travel apps have type to the actuall attractions. For example, if I wanted to find only “temples” or “ancient towns” in nearby area, I would have to search for them manually.
Manually classifying 10,000 attractions is not a feasible task, so I decided to use a Large Language Model (LLM) to help me with this task.
The Solution: Using LLMs to bulk classify the attractions
To categorize each attraction, I used a very simple but effective system prompt. The LLM was instructed to read the description and choose one type from my predefined list of 8 categories.
messages = [
{
"role": "system",
"content": (
"你是景点分类器。读完简介后,按下列 8 类选 **1 个**\n"
"可选 key:\n"
"natural 自然风光\n"
"historical 历史遗址\n"
"religious 宗教场所\n"
"ancient_town 古镇/民俗村\n"
"park 公园/花园\n"
"museum 博物馆 / 展览馆\n"
"entertainment 娱乐休闲\n"
"other 其他\n\n"
"判定思路自行推理:以游客主要动机为准;多重属性取最突出者;无法判断选 other。\n"
"仅输出\njson {\"result\":\"<key>\"},不得包含其他字符。"
)
},
{
"role": "user",
"content": description
}
]
These prompts were sent to the LLM hosted on Groq cloud to efficiently go through the 10,000 attractions. The rate throughput was going on maximum speed, and I was able to classify all the attractions in less than 10 minutes.
The overall processing took around 4 millions tokens, but thanks to Groq’s pricing, the entire process was under a dollar, almost neglectable in cost!
The Results
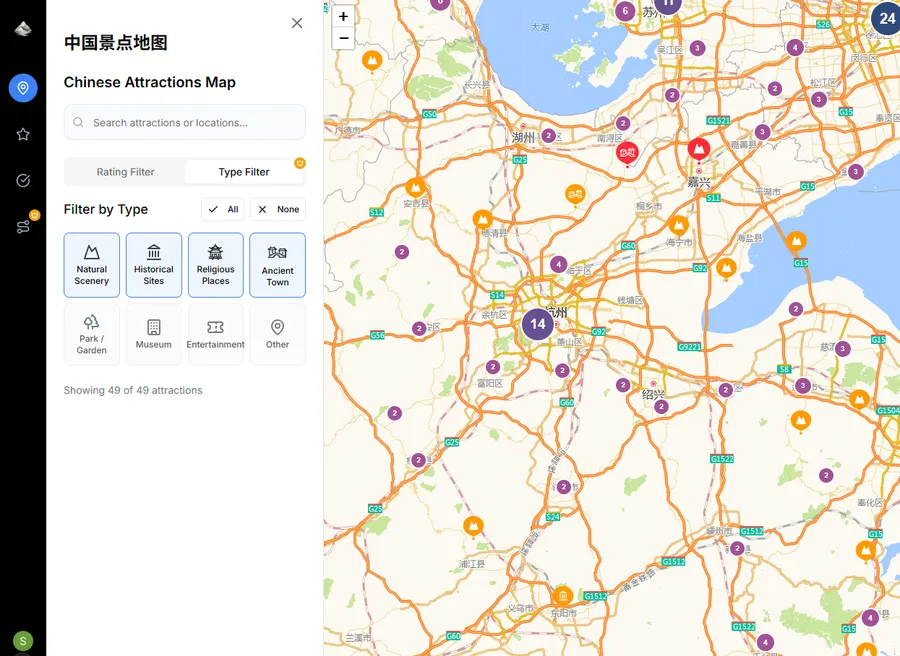
After obtaining the new type property for each attraction, I was able to visiualize the results on a map. Now, users (myself included) can easily filter attractions by the type of place they’re interested in visiting.
It’s a small change from the outside, but it dramatically improves the overall user experience. It’s much easier to plan trips when I can instantly find natural parks, temples, or historic areas without reading through endless lists manually. The use of LLMs in these kind of projects opens a lot of possibilities for automating tedious tasks, that would have been impossible to implement for solo developers like me. Also, the speed of the new feature is impressive, here’s small gif showing the new feature in action!
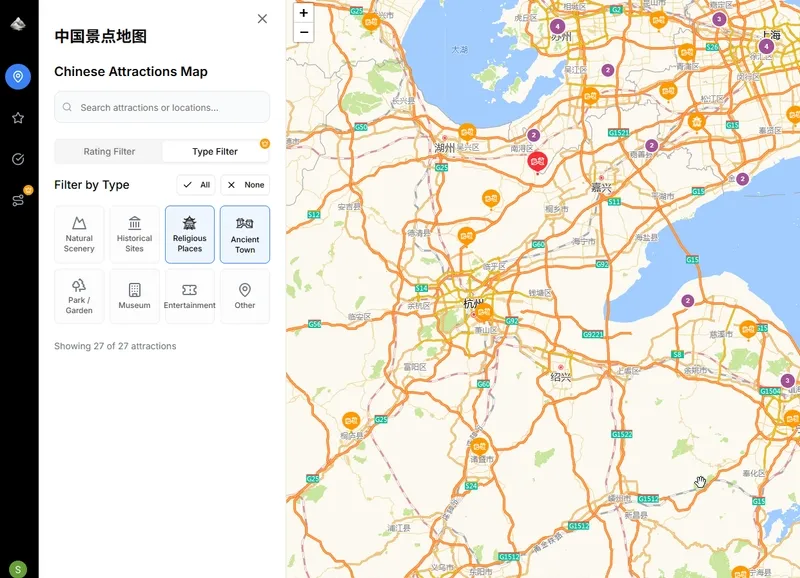
Also, checkout the app in action (beta version): (https://planchinatrips.com).